As described in many previous blog posts, Disnix's purpose is to deploy service-oriented systems -- systems that can be decomposed into inter-connected service components, such as databases, web services, web applications and processes -- to networks of machines.
To use Disnix effectively, two requirements must be met:
Disnix was originally designed to only deploy the (functional) application components (called services in Disnix terminology) of which a service-oriented systems consists, but it was not designed to handle the deployment of any underlying container services.
In my PhD thesis, I called Disnix's problem domain service deployment. Another problem domain that I identified was infrastructure deployment that concerns the deployment of machine configurations, including container services.
The fact that these problem domains are separated means that, if we want to fully deploy a service-oriented system from scratch, we basically need to do infrastructure deployment first, e.g. install a collection of machines with system software and these container services, such as MySQL and Apache Tomcat, and once that is done, we can use these machines as deployment targets for Disnix.
There are a variety of solutions available to automate infrastructure deployment. Most notably, NixOps can be used to automatically deploy networks of NixOS configurations, and (if desired) automatically instantiate virtual machines in a cloud/IaaS environment, such as Amazon EC2.
Although combining NixOps for infrastructure deployment with Disnix for service deployment works great in many scenarios, there are still a number of concerns that are not adequately addressed:
In a Disnix-context, services have no specific meaning or shape and can basically represent anything -- a satellite tool providing a plugin system (called Dysnomia) takes care of most of their deployment steps, such as their activation and deactivation.
A couple of years ago, I have demonstrated with a proof of concept implementation that we can use Disnix and Dysnomia's features to deploy infrastructure components. This deployment approach is also capable of deploying multiple instances of container services to one machine.
Recently, I have revisited that idea again and extended it so that we can now deploy a service-oriented system including most underlying container services with a single command-line instruction.
As described in the introduction, Disnix's purpose is service deployment and not infrastructure deployment. In the past, I have been using a variety of solutions to manage the underlying infrastructure of service-oriented systems:
The idea behind the last approach is that we deploy two systems in sequential order with Disnix -- the former consisting of the container services and the latter of the application services.
For example, if we want to deploy a system that consists of a number of Java web applications and MySQL databases, such as the infamous Disnix StaffTracker example application (Java version), then we must first deploy a system with Disnix that provides the containers: the MySQL DBMS and Apache Tomcat:
As described in earlier blog posts about Disnix, deployments are driven by three configuration files -- the services model captures all distributable components of which the system consists (called services in a Disnix-context), the infrastructure model captures all target machines in the network and their relevant properties, and the distribution model specifies the mappings of services in the services model to the target machines (and container services already available on the machines in the network).
All the container services in the services model provide above refer to systemd services, that in addition to running Apache Tomcat and MySQL, also do the following:
For example, the Nix expression that configures Apache Tomcat has roughly the following structure:
First, the Nix expression will build and configure Apache Tomcat (this is left out of the example to keep it short). After Apache Tomcat has been built and configured, the Nix expression generates the container configuration file and copies the tomcat-webapplication Dysnomia module from the Dysnomia toolset.
The disnix-env command-line instruction shown earlier, deploys container services to target machines in the network, using a bare infrastructure model that does not provide any container services except the init system (which is systemd on NixOS). The profile parameter specifies a Disnix profile to tell the tool that we are deploying a different kind of system than the default.
If the command above succeeds, then we have all required container services at our disposal. The deployment architecture of the resulting system may look as follows:

In the above diagram, the light grey colored boxes correspond to machines in a network, the dark grey boxes to container environments, and white ovals to services.
As you may observe, we have deployed three services -- to the test1 machine we have deployed an Apache Tomcat service (that itself is managed by systemd), and to the test2 machine we have deployed both Apache Tomcat and the MySQL server (both their lifecycles are managed with systemd).
We can run the following command to generate a new infrastructure model that provides the properties of these newly deployed container services:
As shown earlier, the retrieved infrastructure model provides all relevant configuration properties of the MySQL and Apache Tomcat containers that we have just deployed, because they expose their configuration properties via container configuration files.
By using the retrieved infrastructure model and running the following command, we can deploy our web application and database components:
In the above command-line invocation, the services model contains all application components, and the distribution model maps these application components to the corresponding target machines and their containers.
As with the previous disnix-env command invocation, we provide a --profile parameter to tell Disnix that we are deploying a different system. If we would use the same profile parameter as in the previous example, then Disnix will undeploy the container services and tries to upgrade the system with the application services, which will obviously fail.
If the above command succeeds, then we have successfully deployed both the container and application services that our example system requires, resulting in a fully functional and activated system with a deployment architecture that may have the following structure:

As may you may observe by looking at the diagram above, we have deployed a system that consists of a number of MySQL databases, Java web services and Java web applications.
The diagram uses the same notational conventions used in the previous diagram. The arrows denote inter-dependency relationships, telling Disnix that one service depends on another, and that dependency should be deployed first.
The Disnix service container deployment approach that I just described works, but it is not an integrated solution -- it has a limitation that is comparable to the infrastructure and services deployment separation that I have explained earlier. It requires you to run two deployments: one for the containers and one for the services.
In the blog post that I wrote a couple of years ago, I also explained that in order to fully automate the entire process with a single command, this might eventually lead to "a layered deployment approach" -- the idea was to combine several system deployment processes into one. For example, you might want to deploy a service manager in the first layer, the container services for application components in the second, and in the third the application components themselves.
I also argued that it is probably not worth spending a lot of effort in automating multiple deployment layers -- for nearly all systems that I deployed there were only two "layers" that I need to keep track of -- the infrastructure layer providing container services, and a service layer providing the application services. NixOps sufficed as a solution to automate the infrastructure parts for most of my use cases, except for deployment to non-NixOS machines, and deploying multiple instances of container services, which is a very uncommon use case.
However, I got inspired to revisit this problem again after I completed my work described in the previous blog post -- in my previous blog post, I have created a process manager-agnostic service management framework that works with a variety of process managers on a variety of operating systems.
Combining this framework with Disnix, makes it possible to also easily deploy container services (most of them are daemons) to non-NixOS machines, including non-Linux machines, such as macOS and FreeBSD from the same declarative specifications.
Moreover, this framework also provides facilities to easily deploy multiple instances of the same service to the same machine.
Revisiting this problem also made me think about the "layered approach" again, and after some thinking I have dropped the idea. The problem of using layers is that:
After some thinking, I came up with a much simpler approach -- I have introduced a new concept to the Disnix services model that makes it possible to annotate services with a specification of the container services that it provides. This information can be used by application services that need to deploy to this container service.
For example, we can annotate the Apache Tomcat service in the Disnix services model as follows:
In the above example, the simpleAppservingTomcat service refers to an Apache Tomcat server that serves Java web applications for one particular virtual host. The providesContainers property tells Disnix that the service is a container provider, providing a container named: tomcat-webapplication with the following properties:
The other service in the services model (GeolocationService) is a Java web application that should be deployed to a Apache Tomcat container service.
If in a Disnix distribution model, we map the Apache Tomcat service (simpleAppservingTomcat) and the Java web application (GeolocationService) to the same machine:
Disnix will automatically search for a suitable container service provider for each service.
In the above scenario, Disnix knows that simpleAppservingTomcat provides a tomcat-webapplication container. The GeolocationService uses the type: tomcat-webapplication indicating that it needs to deployed to a Apache Tomcat servlet container.
Because these services have been deployed to the same machine Disnix will make sure that Apache Tomcat gets activated before the GeolocationService, and uses the Dysnomia module that is bundled with the simpleAppservingTomcat to handle the deployment of the Java web application.
Furthermore, the properties that simpleAppservingTomcat exposes in the providesContainers attribute set, are automatically propagated as container parameters to the GeolocationService Nix expression, so that it knows where the WAR file should be copied to, to automatically hot-deploy the service.
If Disnix does not detect a service that provides a required container deployed to the same machine, then it will fall back to its original behaviour -- it automatically propagates the properties of a container in the infrastructure model, and assumes the the container service is already deployed by an infrastructure deployment solution.
The notation used for the simpleAppservingTomcat service (shown earlier) refers to an attribute set. An attribute set also makes it possible to specify multiple container instances. However, it is far more common that we only need one single container instance.
Moreover, there is some redundancy -- we need to specify certain properties in two places. Some properties can both belong to a service, as well as the container properties that we want to propagate to the services that require it.
We can also use a shorter notation to expose only one single container:
In the above example, we have rewritten the service configuration of simpleAppserviceTomcat to use the providesContainer attribute referring to a string. This shorter notation will automatically expose all non-reserved service properties as container properties.
For our example above, this means that it will automatically expose httpPort, and catalinaBaseDir and ignores the remaining properties -- these remaining properties have a specific purpose for the Disnix deployment system.
Although the notation above simplifies things considerably, the above example still contains a bit of redundancy -- some of the container properties that we want to expose to application services, also need to be propagated to the constructor function requiring us to specify the same properties twice.
We can eliminate this redundancy by encapsulating the creation of the service properties attribute set a constructor function. With a constructor function, we can simply write:
By applying the techniques described in the previous section to the StaffTracker example (e.g. distributing a simpleAppservingTomcat and mysql to the same machines that host Java web applications and MySQL databases), we can deploy the StaffTracker system including all its required container services with a single command-line instruction:
The corresponding deployment architecture visualization may look as follows:

As you may notice, the above diagram looks very similar to the previously shown deployment architecture diagram of the services layer.
What has been added are the container services -- the ovals with the double borders denote services that are also container providers. The labels describe both the name of the service and the containers that it provides (behind the arrow ->).
Furthermore, all the services that are hosted inside a particular container environment (e.g. tomcat-webapplication) have a local inter-dependency on the corresponding container provider service (e.g. simpleAppservingTomcat), causing Disnix to activate Apache Tomcat before the web applications that are hosted inside it.
Another thing you might notice, is that we have not completely eliminated the dependency on an infrastructure deployment solution -- the MySQL DBMS and Apache Tomcat service are deployed as systemd-unit requiring the presence of systemd on the target system. Systemd should be provided as part of the target Linux distribution, and cannot be managed by Disnix because it runs as PID 1.
One of my motivating reasons to use Disnix as a deployment solution for container services is to be able to deploy multiple instances of them to the same machine. This can also be done in a combined container and application services deployment approach.
To allow, for example, to have two instance of Apache Tomcat to co-exist on one machine, we must configure them in such a way their resources do not conflict:
The above partial services model defines two Apache Tomcat instances, that have been configured to listen to different TCP ports (for example the primary Tomcat instance listens to HTTP traffic on port 8080, whereas the secondary instance listens on port 8081), and serving web applications from a different deployment directories. Because their properties do not conflict, they can co-exist on the same machine.
With the following distribution model, we can deploy multiple container providers to the same machine and distribute application services to them:
In the first four lines of the distribution model shown above, we distribute the container providers. As you may notice, we distribute two MySQL instances that should co-exist on machine test1 and two Apache Tomcat instances that should co-exist on machine test2.
In the remainder of the distribution model, we map Java web applications and MySQL databases to these container providers. As explained in the previous blog post about deploying multiple container service instances, if no container is specified in the distribution model, Disnix will auto map the service to the container that has the same name as the service's type.
In the above example, we have two instances of each container service with a different name. As a result, we need to use the more verbose notation for distribution mappings to instruct Disnix to which container provider we want to deploy the service.
Deploying the system with the following command-line instruction:
results in a running system that may has the following deployment architecture:

As you may notice, we have MySQL databases and Java web application distributed over mutiple container providers residing on the same machine. All services belong to the same system, deployed by a single Disnix command.
By exposing services as container providers in Disnix, my original requirements were met. Because the facilities are very flexible, I also discovered that there is much more I could do.
For example, on more primitive systems that do not have systemd, I could also extend the services and distribution models in such a way that I can deploy supervisord as a process manager first (as a sysvinit-script that does not require any process manager service), then use supervisord to manage MySQL and Apache Tomcat, and then use the Dysnomia plugin system to deploy the databases and Java web applications to these container services managed by supervisord:

As you may notice, the deployment architecture above looks similar to the first combined deployment example, with supervisord added as an extra container provider service.
In addition to managed processes (which the MySQL DBMS and Apache Tomcat services are), any kind of Disnix service can act as a container provider.
An example of such a non-process managed container provider could be Apache Axis2. In the StaffTracker example, all data access is provided by web services. These web services are implemented as Java web applications (WAR files) embedding an Apache Axis2 container that embeds an Axis2 Application Archive (AAR file) providing the web service implementation.
Every web application that is a web service includes its own implementation of Apache Axis2.
It is also possible to deploy a single Axis2 web application to Apache Tomcat, and treat each Axis2 Application Archive as a separate deployment unit using the axis2-webservice identifier as a container provider for any service of the type: axis2-webservice:
In the above partial services model, we have defined two container providers:
The remaining services are Axis2 web services that can be embedded inside the shared Axis2 container.
If we deploy the above example system, e.g.:
may result in the following deployment architecture:

As may be observed when looking at the above architecture diagram, the web services deployed to the test2 machine, use a shared Axis2 container, that is embedded as a Java web application inside Apache Tomcat.
The above system has a far better degree of reuse, because it does not use redundant copies of Apache Axis2 for each web service.
Although it is possible to have a deployment architecture with a shared Axis2 container, this shared approach is not always desirable to use. For example, database connections managed by Apache Tomcat are shared between all web services embedded in an Axis2 container, which is not always desirable from a security point of view.
Moreover, an unstable web service embedded in an Axis2 container might also tear the container down causing the other web services to crash as well. Still, the deployment system does not make it difficult to use a shared approach, when it is desired.
With this new feature addition to Disnix, that can expose services as container providers, it becomes possible to deploy both container services and application services as one integrated system.
Furthermore, it also makes it possible to:
The fact that Disnix can now also deploy containers does not mean that it no longer relies on external infrastructure deployment solutions anymore. For example, you still need target machines at your disposal that have Nix and Disnix installed and need to be remotely connectable, e.g. through SSH. For this, you still require an external infrastructure deployment solution, such as NixOps.
Furthermore, not all container services can be managed by Disnix. For example, systemd, that runs as a system's PID 1, cannot be installed by Disnix. Instead, it must already be provided by the target system's Linux distribution (In NixOS' case it is Nix that deploys it, but it is not managed by Disnix).
And there may also be other reasons why you may still want to use separated deployment processes for container and service deployment. For example, you may want to deploy to container services that cannot be managed by Nix/Disnix, or you may work in an organization in which two different teams take care of the infrastructure and the services.
The new features described in this blog post are part of the current development versions of Dysnomia and Disnix that can be obtained from my GitHub page. These features will become generally available in the next release.
Moreover, I have extended all my public Disnix examples with container deployment support (including the Java-based StaffTracker and composition examples shown in this blog post). These changes currently reside in the servicesascontainers Git branches.
The nix-processmgmt repository contains shared constructor functions for all kinds of system services, e.g. MySQL, Apache HTTP server, PostgreSQL and Apache Tomcat. These functions can be reused amongst all kinds of Disnix projects.
To use Disnix effectively, two requirements must be met:
- A system must be decomposed into independently deployable services, and these services must be packaged with Nix.
- Services may require other services that provide environments with essential facilities to run them. In Disnix terminology, these environments are called containers. For example, to host a MySQL database, Disnix requires a MySQL DBMS as a container, to run a Java web application archive you need a Java Servlet container, such as Apache Tomcat, and to run a daemon it needs a process manager, such as systemd, launchd or supervisord.
Disnix was originally designed to only deploy the (functional) application components (called services in Disnix terminology) of which a service-oriented systems consists, but it was not designed to handle the deployment of any underlying container services.
In my PhD thesis, I called Disnix's problem domain service deployment. Another problem domain that I identified was infrastructure deployment that concerns the deployment of machine configurations, including container services.
The fact that these problem domains are separated means that, if we want to fully deploy a service-oriented system from scratch, we basically need to do infrastructure deployment first, e.g. install a collection of machines with system software and these container services, such as MySQL and Apache Tomcat, and once that is done, we can use these machines as deployment targets for Disnix.
There are a variety of solutions available to automate infrastructure deployment. Most notably, NixOps can be used to automatically deploy networks of NixOS configurations, and (if desired) automatically instantiate virtual machines in a cloud/IaaS environment, such as Amazon EC2.
Although combining NixOps for infrastructure deployment with Disnix for service deployment works great in many scenarios, there are still a number of concerns that are not adequately addressed:
- Infrastructure and service deployment are still two (somewhat) separated processes. Although I have developed an extension toolset (called DisnixOS) to combine Disnix with the deployment concepts of NixOS and NixOps, we still need to run two kinds of deployment procedures. Ideally, it would be nice to fully automate the entire deployment process with only one command.
- Although NixOS (and NixOps that extends NixOS' concepts to networks of machines and the cloud) do a great job in fully automating the deployments of machines, we can only reap their benefits if we can permit ourselves use to NixOS, which is a particular Linux distribution flavour -- sometimes you may need to deploy services to conventional Linux distributions, or different kinds of operating systems (after all, one of the reasons to use service-oriented systems is to be able to use a diverse set of technologies).
The Nix package manager also works on other operating systems than Linux, such macOS, but there is no Nix-based deployment automation solution that can universally deploy infrastructure components to other operating systems (the only other infrastructure deployment solution that provides similar functionality to NixOS is the the nix-darwin repository, that can only be used on macOS). - The NixOS module system does not facilitate the deployment of multiple instances of infrastructure components. Although this is probably a very uncommon use case, it is also possible to run two MySQL DBMS services on one machine and use both of them as Disnix deployment targets for databases.
In a Disnix-context, services have no specific meaning or shape and can basically represent anything -- a satellite tool providing a plugin system (called Dysnomia) takes care of most of their deployment steps, such as their activation and deactivation.
A couple of years ago, I have demonstrated with a proof of concept implementation that we can use Disnix and Dysnomia's features to deploy infrastructure components. This deployment approach is also capable of deploying multiple instances of container services to one machine.
Recently, I have revisited that idea again and extended it so that we can now deploy a service-oriented system including most underlying container services with a single command-line instruction.
About infrastructure deployment solutions
As described in the introduction, Disnix's purpose is service deployment and not infrastructure deployment. In the past, I have been using a variety of solutions to manage the underlying infrastructure of service-oriented systems:
- In the very beginning, while working on my master thesis internship (in which I built the first prototype version of Disnix), there was not much automation at all -- for most of my testing activities I manually created VirtualBox virtual machines and manually installed NixOS on them, with all essential container servers, such as Apache Tomcat and MySQL, because these were the container services that my target system required.
Even after some decent Nix-based automated solutions appeared, I still ended up doing manual deployments for non-NixOS machines. For example, I still remember the steps I had to perform to prepare myself for the demo I gave at NixCon 2015, in which I configured a small heterogeneous network consisting of an Ubuntu, NixOS, and Windows machine. It took me many hours of preparation time to get the demo right. - Some time later, for a research paper about declarative deployment and testing, we have developed a tool called nixos-deploy-network that deploys NixOS configurations in a network of machines and is driven by a networked NixOS configuration file.
- Around the same time, I have also developed a similar tool called: disnixos-deploy-network that uses Disnix's deployment mechanisms to remotely deploy a network of NixOS configurations. It was primarily developed to show that Disnix's plugin system: Dysnomia, could also treat entire NixOS configurations as services.
- When NixOps appeared (initially it was called Charon), I have also created facilities in the DisnixOS toolset to integrate with it -- for example DisnixOS can automatically convert a NixOps configuration to a Disnix infrastructure model.
- And finally, I have created a proof of concept implementation that shows that Disnix can also treat every container service as a Disnix service and deploy it.
The idea behind the last approach is that we deploy two systems in sequential order with Disnix -- the former consisting of the container services and the latter of the application services.
For example, if we want to deploy a system that consists of a number of Java web applications and MySQL databases, such as the infamous Disnix StaffTracker example application (Java version), then we must first deploy a system with Disnix that provides the containers: the MySQL DBMS and Apache Tomcat:
$ disnix-env -s services-containers.nix \
-i infrastructure-bare.nix \
-d distribution-containers.nix \
--profile containers
As described in earlier blog posts about Disnix, deployments are driven by three configuration files -- the services model captures all distributable components of which the system consists (called services in a Disnix-context), the infrastructure model captures all target machines in the network and their relevant properties, and the distribution model specifies the mappings of services in the services model to the target machines (and container services already available on the machines in the network).
All the container services in the services model provide above refer to systemd services, that in addition to running Apache Tomcat and MySQL, also do the following:
- They bundle a Dysnomia plugin that can be used to manage the life-cycles of Java web applications and MySQL databases.
- They bundle a Dysnomia container configuration file capturing all relevant container configuration properties, such as the MySQL TCP port the daemon listens to, and the Tomcat web application deployment directory.
For example, the Nix expression that configures Apache Tomcat has roughly the following structure:
{stdenv, dysnomia, httpPort, catalinaBaseDir, instanceSuffix ? ""}:
stdenv.mkDerivation {
name = "simpleAppservingTomcat";
...
postInstall = ''
# Add Dysnomia container configuration file for a Tomcat web application
mkdir -p $out/etc/dysnomia/containers
cat > $out/etc/dysnomia/containers/tomcat-webapplication${instanceSuffix} <<EOF
tomcatPort=${toString httpPort}
catalinaBaseDir=${catalinaBaseDir}
EOF
# Copy the Dysnomia module that manages an Apache Tomcat web application
mkdir -p $out/libexec/dysnomia
ln -s ${dysnomia}/libexec/dysnomia/tomcat-webapplication $out/libexec/dysnomia
'';
}
First, the Nix expression will build and configure Apache Tomcat (this is left out of the example to keep it short). After Apache Tomcat has been built and configured, the Nix expression generates the container configuration file and copies the tomcat-webapplication Dysnomia module from the Dysnomia toolset.
The disnix-env command-line instruction shown earlier, deploys container services to target machines in the network, using a bare infrastructure model that does not provide any container services except the init system (which is systemd on NixOS). The profile parameter specifies a Disnix profile to tell the tool that we are deploying a different kind of system than the default.
If the command above succeeds, then we have all required container services at our disposal. The deployment architecture of the resulting system may look as follows:

In the above diagram, the light grey colored boxes correspond to machines in a network, the dark grey boxes to container environments, and white ovals to services.
As you may observe, we have deployed three services -- to the test1 machine we have deployed an Apache Tomcat service (that itself is managed by systemd), and to the test2 machine we have deployed both Apache Tomcat and the MySQL server (both their lifecycles are managed with systemd).
We can run the following command to generate a new infrastructure model that provides the properties of these newly deployed container services:
$ disnix-capture-infra infrastructure-bare.nix > infrastructure.nix
As shown earlier, the retrieved infrastructure model provides all relevant configuration properties of the MySQL and Apache Tomcat containers that we have just deployed, because they expose their configuration properties via container configuration files.
By using the retrieved infrastructure model and running the following command, we can deploy our web application and database components:
$ disnix-env -s services.nix \
-i infrastructure.nix \
-d distribution.nix \
--profile services
In the above command-line invocation, the services model contains all application components, and the distribution model maps these application components to the corresponding target machines and their containers.
As with the previous disnix-env command invocation, we provide a --profile parameter to tell Disnix that we are deploying a different system. If we would use the same profile parameter as in the previous example, then Disnix will undeploy the container services and tries to upgrade the system with the application services, which will obviously fail.
If the above command succeeds, then we have successfully deployed both the container and application services that our example system requires, resulting in a fully functional and activated system with a deployment architecture that may have the following structure:

As may you may observe by looking at the diagram above, we have deployed a system that consists of a number of MySQL databases, Java web services and Java web applications.
The diagram uses the same notational conventions used in the previous diagram. The arrows denote inter-dependency relationships, telling Disnix that one service depends on another, and that dependency should be deployed first.
Exposing services as containers
The Disnix service container deployment approach that I just described works, but it is not an integrated solution -- it has a limitation that is comparable to the infrastructure and services deployment separation that I have explained earlier. It requires you to run two deployments: one for the containers and one for the services.
In the blog post that I wrote a couple of years ago, I also explained that in order to fully automate the entire process with a single command, this might eventually lead to "a layered deployment approach" -- the idea was to combine several system deployment processes into one. For example, you might want to deploy a service manager in the first layer, the container services for application components in the second, and in the third the application components themselves.
I also argued that it is probably not worth spending a lot of effort in automating multiple deployment layers -- for nearly all systems that I deployed there were only two "layers" that I need to keep track of -- the infrastructure layer providing container services, and a service layer providing the application services. NixOps sufficed as a solution to automate the infrastructure parts for most of my use cases, except for deployment to non-NixOS machines, and deploying multiple instances of container services, which is a very uncommon use case.
However, I got inspired to revisit this problem again after I completed my work described in the previous blog post -- in my previous blog post, I have created a process manager-agnostic service management framework that works with a variety of process managers on a variety of operating systems.
Combining this framework with Disnix, makes it possible to also easily deploy container services (most of them are daemons) to non-NixOS machines, including non-Linux machines, such as macOS and FreeBSD from the same declarative specifications.
Moreover, this framework also provides facilities to easily deploy multiple instances of the same service to the same machine.
Revisiting this problem also made me think about the "layered approach" again, and after some thinking I have dropped the idea. The problem of using layers is that:
- We need to develop another tool that integrates the deployment processes of all layers into one. In addition to the fact that we need to implement more automation, this introduces many additional technical challenges -- for example, if we want to deploy three layers and the deployment of the second fails, how are we going to do a rollback?
- A layered approach is somewhat "imperative" -- each layer deploys services that include Dysnomia modules and Dysnomia container configuration files. The Disnix service on each target machine performs a lookup in the Nix profile that contains all packages of the containers layer to find the required Dysnomia modules and container configuration files.
Essentially, Dysnomia modules and container configurations are stored in a global namespace. This means the order in which the deployment of the layers is executed is important and that each layer can imperatively modify the behaviour of each Dysnomia module. - Because we need to deploy the system on layer-by-layer basis, we cannot for example, deploy multiple services in another layer that have no dependency in parallel, making a deployment process slower than it should be.
After some thinking, I came up with a much simpler approach -- I have introduced a new concept to the Disnix services model that makes it possible to annotate services with a specification of the container services that it provides. This information can be used by application services that need to deploy to this container service.
For example, we can annotate the Apache Tomcat service in the Disnix services model as follows:
{ pkgs, system, distribution, invDistribution
, stateDir ? "/var"
, runtimeDir ? "${stateDir}/run"
, logDir ? "${stateDir}/log"
, cacheDir ? "${stateDir}/cache"
, tmpDir ? (if stateDir == "/var" then "/tmp" else "${stateDir}/tmp")
, forceDisableUserChange ? false
, processManager ? "systemd"
}:
let
constructors = import ../../../nix-processmgmt/examples/services-agnostic/constructors.nix {
inherit pkgs stateDir runtimeDir logDir cacheDir tmpDir forceDisableUserChange processManager;
};
in
rec {
simpleAppservingTomcat = rec {
name = "simpleAppservingTomcat";
pkg = constructors.simpleAppservingTomcat {
inherit httpPort;
commonLibs = [ "${pkgs.mysql_jdbc}/share/java/mysql-connector-java.jar" ];
};
httpPort = 8080;
catalinaBaseDir = "/var/tomcat/webapps";
type = "systemd-unit";
providesContainers = {
tomcat-webapplication = {
httpPort = 8080;
catalinaBaseDir = "/var/tomcat/webapps";
};
};
};
GeolocationService = {
name = "GeolocationService";
pkg = customPkgs.GeolocationService;
dependsOn = {};
type = "tomcat-webapplication";
};
...
}
In the above example, the simpleAppservingTomcat service refers to an Apache Tomcat server that serves Java web applications for one particular virtual host. The providesContainers property tells Disnix that the service is a container provider, providing a container named: tomcat-webapplication with the following properties:
- For HTTP traffic, Apache Tomcat should listen on TCP port 8080
- The Java web application archives (WAR files) should be deployed to the Catalina Servlet container. By copying the WAR files to the /var/tomcat/webapps directory, they should be automatically hot-deployed.
The other service in the services model (GeolocationService) is a Java web application that should be deployed to a Apache Tomcat container service.
If in a Disnix distribution model, we map the Apache Tomcat service (simpleAppservingTomcat) and the Java web application (GeolocationService) to the same machine:
{infrastructure}:
{
simpleAppservingTomcat = [ infrastructure.test1 ];
GeolocationService = [ infrastructure.test1 ];
}
Disnix will automatically search for a suitable container service provider for each service.
In the above scenario, Disnix knows that simpleAppservingTomcat provides a tomcat-webapplication container. The GeolocationService uses the type: tomcat-webapplication indicating that it needs to deployed to a Apache Tomcat servlet container.
Because these services have been deployed to the same machine Disnix will make sure that Apache Tomcat gets activated before the GeolocationService, and uses the Dysnomia module that is bundled with the simpleAppservingTomcat to handle the deployment of the Java web application.
Furthermore, the properties that simpleAppservingTomcat exposes in the providesContainers attribute set, are automatically propagated as container parameters to the GeolocationService Nix expression, so that it knows where the WAR file should be copied to, to automatically hot-deploy the service.
If Disnix does not detect a service that provides a required container deployed to the same machine, then it will fall back to its original behaviour -- it automatically propagates the properties of a container in the infrastructure model, and assumes the the container service is already deployed by an infrastructure deployment solution.
Simplifications
The notation used for the simpleAppservingTomcat service (shown earlier) refers to an attribute set. An attribute set also makes it possible to specify multiple container instances. However, it is far more common that we only need one single container instance.
Moreover, there is some redundancy -- we need to specify certain properties in two places. Some properties can both belong to a service, as well as the container properties that we want to propagate to the services that require it.
We can also use a shorter notation to expose only one single container:
simpleAppservingTomcat = rec {
name = "simpleAppservingTomcat";
pkg = constructors.simpleAppservingTomcat {
inherit httpPort;
commonLibs = [ "${pkgs.mysql_jdbc}/share/java/mysql-connector-java.jar" ];
};
httpPort = 8080;
catalinaBaseDir = "/var/tomcat/webapps";
type = "systemd-unit";
providesContainer = "tomcat-webapplication";
};
In the above example, we have rewritten the service configuration of simpleAppserviceTomcat to use the providesContainer attribute referring to a string. This shorter notation will automatically expose all non-reserved service properties as container properties.
For our example above, this means that it will automatically expose httpPort, and catalinaBaseDir and ignores the remaining properties -- these remaining properties have a specific purpose for the Disnix deployment system.
Although the notation above simplifies things considerably, the above example still contains a bit of redundancy -- some of the container properties that we want to expose to application services, also need to be propagated to the constructor function requiring us to specify the same properties twice.
We can eliminate this redundancy by encapsulating the creation of the service properties attribute set a constructor function. With a constructor function, we can simply write:
simpleAppservingTomcat = constructors.simpleAppservingTomcat {
httpPort = 8080;
commonLibs = [ "${pkgs.mysql_jdbc}/share/java/mysql-connector-java.jar" ];
type = "systemd-unit";
};
Example: deploying container and application services as one system
By applying the techniques described in the previous section to the StaffTracker example (e.g. distributing a simpleAppservingTomcat and mysql to the same machines that host Java web applications and MySQL databases), we can deploy the StaffTracker system including all its required container services with a single command-line instruction:
$ disnix-env -s services-with-containers.nix \
-i infrastructure-bare.nix \
-d distribution-with-containers.nix
The corresponding deployment architecture visualization may look as follows:

As you may notice, the above diagram looks very similar to the previously shown deployment architecture diagram of the services layer.
What has been added are the container services -- the ovals with the double borders denote services that are also container providers. The labels describe both the name of the service and the containers that it provides (behind the arrow ->).
Furthermore, all the services that are hosted inside a particular container environment (e.g. tomcat-webapplication) have a local inter-dependency on the corresponding container provider service (e.g. simpleAppservingTomcat), causing Disnix to activate Apache Tomcat before the web applications that are hosted inside it.
Another thing you might notice, is that we have not completely eliminated the dependency on an infrastructure deployment solution -- the MySQL DBMS and Apache Tomcat service are deployed as systemd-unit requiring the presence of systemd on the target system. Systemd should be provided as part of the target Linux distribution, and cannot be managed by Disnix because it runs as PID 1.
Example: deploying multiple container service instances and application services
One of my motivating reasons to use Disnix as a deployment solution for container services is to be able to deploy multiple instances of them to the same machine. This can also be done in a combined container and application services deployment approach.
To allow, for example, to have two instance of Apache Tomcat to co-exist on one machine, we must configure them in such a way their resources do not conflict:
{ pkgs, system, distribution, invDistribution
, stateDir ? "/var"
, runtimeDir ? "${stateDir}/run"
, logDir ? "${stateDir}/log"
, cacheDir ? "${stateDir}/cache"
, tmpDir ? (if stateDir == "/var" then "/tmp" else "${stateDir}/tmp")
, forceDisableUserChange ? false
, processManager ? "systemd"
}:
let
constructors = import ../../../nix-processmgmt/examples/service-containers-agnostic/constructors.nix {
inherit pkgs stateDir runtimeDir logDir cacheDir tmpDir forceDisableUserChange processManager;
};
in
rec {
simpleAppservingTomcat-primary = constructors.simpleAppservingTomcat {
instanceSuffix = "-primary";
httpPort = 8080;
httpsPort = 8443;
serverPort = 8005;
ajpPort = 8009;
commonLibs = [ "${pkgs.mysql_jdbc}/share/java/mysql-connector-java.jar" ];
type = "systemd-unit";
};
simpleAppservingTomcat-secondary = constructors.simpleAppservingTomcat {
instanceSuffix = "-secondary";
httpPort = 8081;
httpsPort = 8444;
serverPort = 8006;
ajpPort = 8010;
commonLibs = [ "${pkgs.mysql_jdbc}/share/java/mysql-connector-java.jar" ];
type = "systemd-unit";
};
...
}
The above partial services model defines two Apache Tomcat instances, that have been configured to listen to different TCP ports (for example the primary Tomcat instance listens to HTTP traffic on port 8080, whereas the secondary instance listens on port 8081), and serving web applications from a different deployment directories. Because their properties do not conflict, they can co-exist on the same machine.
With the following distribution model, we can deploy multiple container providers to the same machine and distribute application services to them:
{infrastructure}:
{
# Container providers
mysql-primary = [ infrastructure.test1 ];
mysql-secondary = [ infrastructure.test1 ];
simpleAppservingTomcat-primary = [ infrastructure.test2 ];
simpleAppservingTomcat-secondary = [ infrastructure.test2 ];
# Application components
GeolocationService = {
targets = [
{ target = infrastructure.test2;
container = "tomcat-webapplication-primary";
}
];
};
RoomService = {
targets = [
{ target = infrastructure.test2;
container = "tomcat-webapplication-secondary";
}
];
};
StaffTracker = {
targets = [
{ target = infrastructure.test2;
container = "tomcat-webapplication-secondary";
}
];
};
staff = {
targets = [
{ target = infrastructure.test1;
container = "mysql-database-secondary";
}
];
};
zipcodes = {
targets = [
{ target = infrastructure.test1;
container = "mysql-database-primary";
}
];
};
...
}
In the first four lines of the distribution model shown above, we distribute the container providers. As you may notice, we distribute two MySQL instances that should co-exist on machine test1 and two Apache Tomcat instances that should co-exist on machine test2.
In the remainder of the distribution model, we map Java web applications and MySQL databases to these container providers. As explained in the previous blog post about deploying multiple container service instances, if no container is specified in the distribution model, Disnix will auto map the service to the container that has the same name as the service's type.
In the above example, we have two instances of each container service with a different name. As a result, we need to use the more verbose notation for distribution mappings to instruct Disnix to which container provider we want to deploy the service.
Deploying the system with the following command-line instruction:
$ disnix-env -s services-with-multicontainers.nix \
-i infrastructure-bare.nix \
-d distribution-with-multicontainers.nix
results in a running system that may has the following deployment architecture:
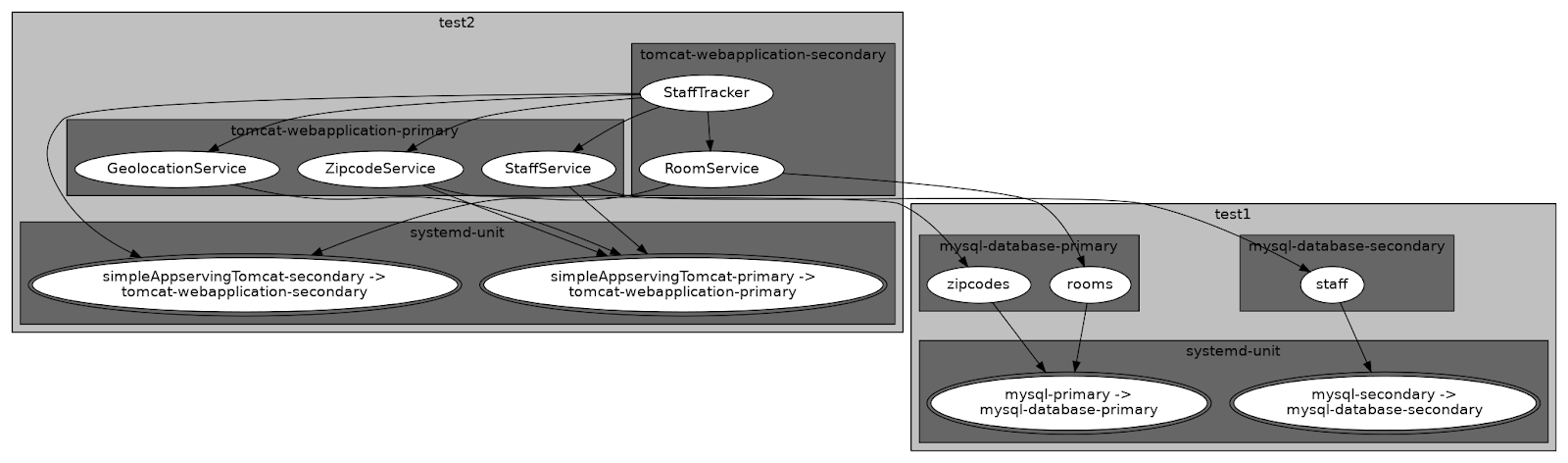
As you may notice, we have MySQL databases and Java web application distributed over mutiple container providers residing on the same machine. All services belong to the same system, deployed by a single Disnix command.
A more extreme example: multiple process managers
By exposing services as container providers in Disnix, my original requirements were met. Because the facilities are very flexible, I also discovered that there is much more I could do.
For example, on more primitive systems that do not have systemd, I could also extend the services and distribution models in such a way that I can deploy supervisord as a process manager first (as a sysvinit-script that does not require any process manager service), then use supervisord to manage MySQL and Apache Tomcat, and then use the Dysnomia plugin system to deploy the databases and Java web applications to these container services managed by supervisord:

As you may notice, the deployment architecture above looks similar to the first combined deployment example, with supervisord added as an extra container provider service.
More efficient reuse: expose any kind of service as container provider
In addition to managed processes (which the MySQL DBMS and Apache Tomcat services are), any kind of Disnix service can act as a container provider.
An example of such a non-process managed container provider could be Apache Axis2. In the StaffTracker example, all data access is provided by web services. These web services are implemented as Java web applications (WAR files) embedding an Apache Axis2 container that embeds an Axis2 Application Archive (AAR file) providing the web service implementation.
Every web application that is a web service includes its own implementation of Apache Axis2.
It is also possible to deploy a single Axis2 web application to Apache Tomcat, and treat each Axis2 Application Archive as a separate deployment unit using the axis2-webservice identifier as a container provider for any service of the type: axis2-webservice:
{ pkgs, system, distribution, invDistribution
, stateDir ? "/var"
, runtimeDir ? "${stateDir}/run"
, logDir ? "${stateDir}/log"
, cacheDir ? "${stateDir}/cache"
, tmpDir ? (if stateDir == "/var" then "/tmp" else "${stateDir}/tmp")
, forceDisableUserChange ? false
, processManager ? "systemd"
}:
let
constructors = import ../../../nix-processmgmt/examples/service-containers-agnostic/constructors.nix {
inherit pkgs stateDir runtimeDir logDir cacheDir tmpDir forceDisableUserChange processManager;
};
customPkgs = import ../top-level/all-packages.nix {
inherit system pkgs stateDir;
};
in
rec {
### Container providers
simpleAppservingTomcat = constructors.simpleAppservingTomcat {
httpPort = 8080;
commonLibs = [ "${pkgs.mysql_jdbc}/share/java/mysql-connector-java.jar" ];
type = "systemd-unit";
};
axis2 = customPkgs.axis2 {};
### Web services
HelloService = {
name = "HelloService";
pkg = customPkgs.HelloService;
dependsOn = {};
type = "axis2-webservice";
};
HelloWorldService = {
name = "HelloWorldService";
pkg = customPkgs.HelloWorldService;
dependsOn = {
inherit HelloService;
};
type = "axis2-webservice";
};
...
}
In the above partial services model, we have defined two container providers:
- simpleAppservingTomcat that provides a Servlet container in which Java web applications (WAR files) can be hosted.
- The axis2 service is a Java web application that acts as a container provider for Axis2 web services.
The remaining services are Axis2 web services that can be embedded inside the shared Axis2 container.
If we deploy the above example system, e.g.:
$ disnix-env -s services-optimised.nix \
-i infrastructure-bare.nix \
-d distribution-optimised.nix
may result in the following deployment architecture:
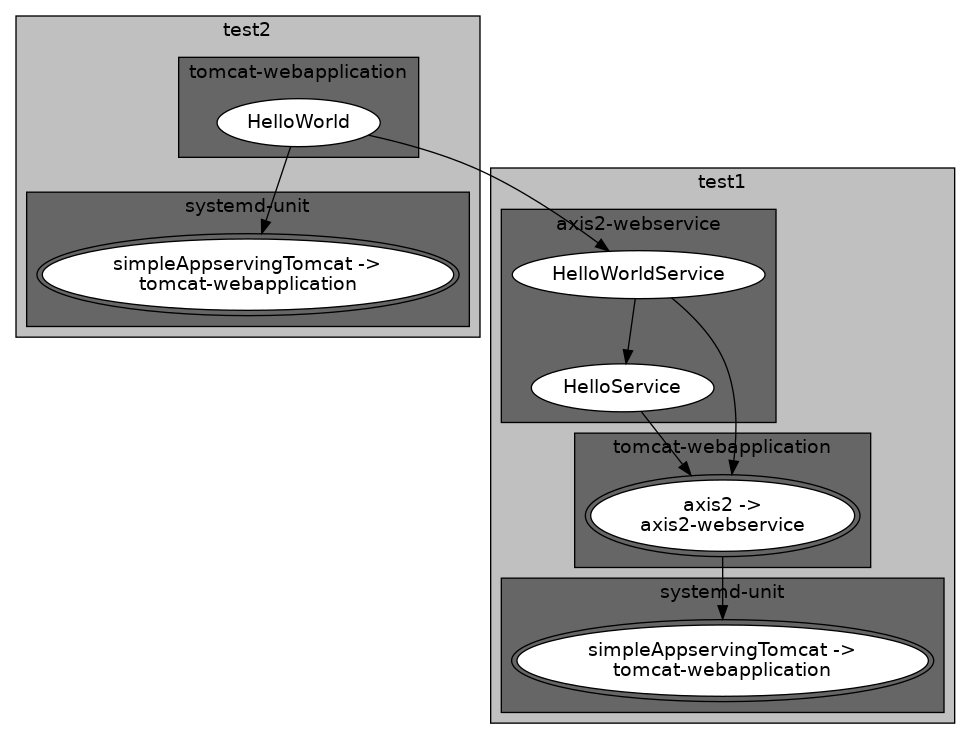
As may be observed when looking at the above architecture diagram, the web services deployed to the test2 machine, use a shared Axis2 container, that is embedded as a Java web application inside Apache Tomcat.
The above system has a far better degree of reuse, because it does not use redundant copies of Apache Axis2 for each web service.
Although it is possible to have a deployment architecture with a shared Axis2 container, this shared approach is not always desirable to use. For example, database connections managed by Apache Tomcat are shared between all web services embedded in an Axis2 container, which is not always desirable from a security point of view.
Moreover, an unstable web service embedded in an Axis2 container might also tear the container down causing the other web services to crash as well. Still, the deployment system does not make it difficult to use a shared approach, when it is desired.
Conclusion
With this new feature addition to Disnix, that can expose services as container providers, it becomes possible to deploy both container services and application services as one integrated system.
Furthermore, it also makes it possible to:
- Deploy multiple instances of container services and deploy services to them.
- For process-based service containers, we can combine the process manager-agostic framework described in the previous blog post, so that we can use them with any process manager on any operating system that it supports.
The fact that Disnix can now also deploy containers does not mean that it no longer relies on external infrastructure deployment solutions anymore. For example, you still need target machines at your disposal that have Nix and Disnix installed and need to be remotely connectable, e.g. through SSH. For this, you still require an external infrastructure deployment solution, such as NixOps.
Furthermore, not all container services can be managed by Disnix. For example, systemd, that runs as a system's PID 1, cannot be installed by Disnix. Instead, it must already be provided by the target system's Linux distribution (In NixOS' case it is Nix that deploys it, but it is not managed by Disnix).
And there may also be other reasons why you may still want to use separated deployment processes for container and service deployment. For example, you may want to deploy to container services that cannot be managed by Nix/Disnix, or you may work in an organization in which two different teams take care of the infrastructure and the services.
Availability
The new features described in this blog post are part of the current development versions of Dysnomia and Disnix that can be obtained from my GitHub page. These features will become generally available in the next release.
Moreover, I have extended all my public Disnix examples with container deployment support (including the Java-based StaffTracker and composition examples shown in this blog post). These changes currently reside in the servicesascontainers Git branches.
The nix-processmgmt repository contains shared constructor functions for all kinds of system services, e.g. MySQL, Apache HTTP server, PostgreSQL and Apache Tomcat. These functions can be reused amongst all kinds of Disnix projects.
by Sander van der Burg (noreply@blogger.com) at April 30, 2020 08:39 PM

